
Ghosted Object is a new way to manage objects in memory. It permit to build a (very) high performance, latency free, persistent, transactional in-virtual memory object repository to manage up to hundreds gigabytes of C# objects with the ease of a simple dictionnary.
Ghosted Object is not a new database engine : it is a new C# data structure. The Ghosted Object concept change the low level memory object layout inherited from the C language 40 years ago. It changes the way instances of classes are managed in memory. This objects are faster to manage than .Net objects aggregations in many use cases, especially to manage classical business data entities.
Ghosted Object open the way to fast and easy to use persistent transactional object repository. This repository is like an embedded object databases, where objects collections are not transitory copy of data stored in a database, but are the database themselves. It is not an in-memory database like Redis because there is no more pull and push of data, no data copy or serialization to access or store objects. Because there is no latency, object access methods are not asynchronous. A classical back-end can avoid async keyword. It can be used not only as an embedded database, but also for object collections management where objects have multiple versions. Beyond persistence, manage transactional object collections can simplified high concurrency scenarios code.
Actual Ghosted Object implementation
This first version is for C# .Net language, but this approach can be implemented in any programming language for better overall performances and convenience of transactional programming model at object level. It can be seen as a technological breakthrough, pushing a new small step in Moore law by doing more data processing with the same hardware. This C# implementation is hand made and do not need any specific .Net runtime or CLR tweak to work. Ideally, it could be integrated directly as a CLR extension and compiler language sugar to make it as transparent as record data structure is. Time will tell.
Actual Ghost Repository implementation
This first Ghost Repository implementation is a layer on top of LMDB, the (probably) fastest key/value store (in read scenarios and on Linux). LMDB had a game changer feature : the “zero copy” and “pointer based” data access mechanism permitted by the “copy-on-write” MVCC strategy. This permit to use it as a sophisticated transactional memory manager. If you do not read data in place but copy it in another place each time you access it, you are not using LMDB the right way. It is that simple. Ghosted Objects are compliant with this access mode, and it is faster than any database engine on the planet.
What can be done ?
Beyond the underlying research topic (high performance in memory object management), Ghosted Object is a production ready technology :
- First, you define the classes you want manage in repositories. In the first implementation, you use a T4 file code generator. This classes are composed of properties of various types : int, long, double, strings, arrays, etc. You can define relations between your objects as collections and aggregations properties in the classes.
- Then, you open a object repository, create instances of this classes and add it to the repository using a write transaction. To retrieve it, you have one table for each type of object. You can use all linq feature to query this tables.
- To modify an object, you simply retreive it, change his properties value, aggregations and collections, and simply commit the transaction. There is no update method to call. Objects are the data.
- You can open hundreds of read only transactions concurrently to serialized write transactions. You can have one write transaction at a time, and many read transactions. Writes transactions do not freeze read ones. Each transaction see the repository in the state it was when she was opened, even if there is many write transactions making changes at the same time : during a transaction, all is stable.
- This repository can be only in memory, or persisted on disk. You can create and add billions of objects in the repository, the total size of the objects can be larger than the available memory. When opening a persisted repository, there is no preloading : all objects are instantly available and streamed from disk at light speed, transparently.
- Like any in memory repository, it is fast : each second, each thread can retreive and enumerate millions of objects. There is no concurency concern, nor garbage collector freeze, even with undreds gigabytes of objects in the repository.
- Zero latency to access data mean that you don’t need to apply async programming model (and avoid state machines and syntax linked to async mathods, what is sometime described as a code “cancer”).
Behind the scene, in few words
In a POCO structure (Plain Old C# Object), fields like strings or arrays of primitive types (int, double…) or arrays of structures are independent objects. A class have memory pointers referencing this sub structures as independent objects.
In a Ghosted Object, both primitive type fields and arrays are stored in a single memory block. Arrays are managed as fast sub allocations. In .Net, it use the native memory, not the managed one.
Using POCO, if you have a class with 5 string properties, you’ll have to manage 6 objects memory blocks and their .net headers and manage 5 pointers in the main instance. Using a Ghosted Object, you have only one memory block allocated in native memory. To access this memory block, you use a single Body class instance. The Body is the C# class instance to manage the Ghost, and the Ghost is the memory block that store the properties value.
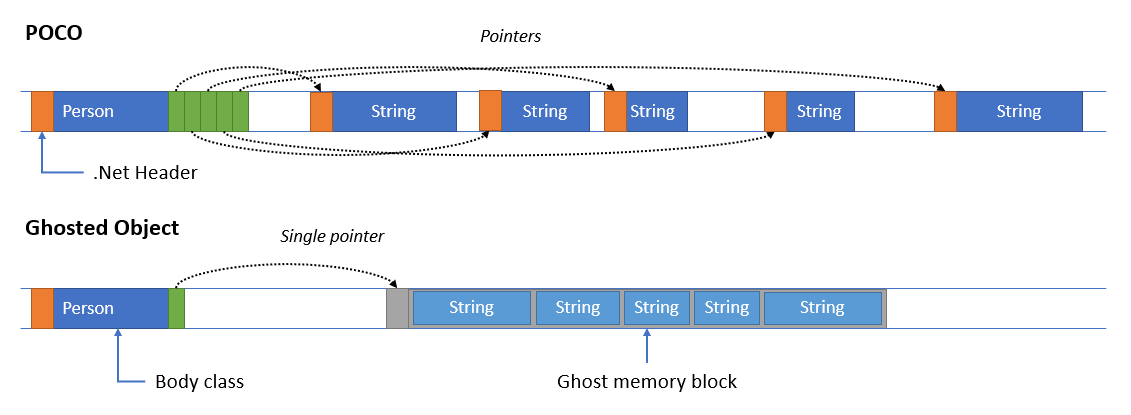
This new structure type have many benefits. For example :
- Less memory operations which lead to faster basic operations like creation and properties assignations than using POCO.
- Lower garbage work, or zero garbage work if we manage only the Ghosts in a dedicated Repository.
- Easy comparison, deep copy and immutability, because all values are in a single memory block.
- No serialization : you can take “as this” a Ghost and store it in a file or send it on a network.
But the biggest step ahead is that this data structure can be managed in a dedicated Ghost Repository in which you access the properties values of Ghosted Objects without any memory copy (or only few). This Repository is in protected virtual memory, transactional using MVCC (like snapshot mode), persistent. It is ACID and support lock free Write and Read Transactions concurrency. Underlying, it use the famous LMDB key-value store, which is the perfect complement to Ghosted Object data structure. It is (really) fast, as fast as any in-memory B+Tree data structure. The data can be many time larger than the available random access memory. Again, what is different from classical database, in memory database or ORM like Entity Framework, is the fact that objects are not transitory copy of stored data, they are the stored data. If a Ghosted Object is flat structure, a Ghost Repository expend the concept to establish relationships between objects to design a real world data schema including lifecycle rules, indexes and graph oriented processing.
The combination of Ghosted Object and Ghost Repository open the way to new programming models to manage gigabytes or terabytes of in-memory C# objects and to works in a transactional way at object level. It ease concurrency programming with transactions at object level and an optional immutability.
And again, it can be up to three level of magnitude faster than using classical databases.
Basic sample
First, you define the Ghost itself in a .tt (T4 code generation) file :

After that, you can use it like any other C# class :

Then, you can insert it a Ghost Repository :

In the same store space, you can manage simple key/value tables :

